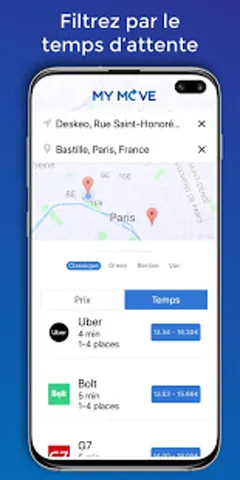
MyMove, c’est un comparateur de tarifs VTC pour Paris et l’Île-de-France. L’utilisateur entre un départ et une destination, et l’app affiche en temps réel les prix et temps d’attente chez Uber, Kapten, Bolt, G7, LeCab et Heetch. Il choisit le moins cher ou le plus rapide, et on le redirige vers l’app du fournisseur. Pour MySam, la réservation se fait directement dans l’app.

J’ai repris le projet en début d’année. L’architecture existait déjà (microservices, Cloud Run, React Native) mais le code avait été laissé dans un état fragile. Pas de types, peu de gestion d’erreurs, des tokens en dur, des retry naïfs. Mon boulot : reprendre la direction technique et consolider le code pour que l’ensemble tienne en production.
Cet article revient sur les défis de cette architecture, les choix techniques hérités et ceux que j’ai faits, et ce que ça implique de scraper cinq services de VTC qui n’ont aucune envie qu’on les scrape.
Le paysage VTC parisien
Le marché parisien est fragmenté. Uber domine en volume, mais les alternatives ne manquent pas : Kapten (ex-Chauffeur Privé, racheté par Daimler en 2019), Bolt (ex-Taxify, l’estonien agressif sur les prix), G7 (le géant historique du taxi parisien), Heetch (le favori des noctambules), LeCab (positionnement premium, tarif fixe garanti). Et MySam, plus confidentiel, seul à proposer une API propre et documentée.
Pour un même trajet Paris-Roissy, l’écart de prix va de 1 à 2 selon le fournisseur et l’heure. Sauf que personne ne peut comparer sans ouvrir cinq apps. MyMove règle ce problème.
L’architecture : cinq microservices et un chef d’orchestre
Un microservice par fournisseur VTC, plus une API centrale pour l’authentification, l’historique et le stockage. Chaque microservice est un petit serveur HTTP qui sait parler à un seul fournisseur. L’app mobile les interroge en parallèle et collecte les résultats via Firebase Firestore.
Chaque microservice est autonome : son propre Dockerfile, son propre port, son propre Makefile de déploiement. On peut redéployer bolt-api sans toucher à g7-api. Ça paraît évident dit comme ça, mais quand un fournisseur change son API du jour au lendemain (et ça arrive souvent), c’est une vraie bouée.
Cloud Run : un héritage bien tombé
Cloud Run n’était pas mon choix. C’était déjà en place quand j’ai récupéré le projet. Le service venait de passer en GA en novembre 2019, et l’équipe précédente avait sauté dessus assez tôt. Avec le recul, c’est adapté pour ce type d’architecture.
On pousse un container Docker, Cloud Run le fait tourner, le scale automatiquement (y compris à zéro quand il n’y a pas de trafic), et on paye à l’usage. Pour des microservices qui répondent à des requêtes HTTP courtes, interroger un fournisseur et renvoyer un prix, c’est bien dimensionné.
# Déploiement de bolt-api sur Cloud Run
prod:
gcloud builds submit --tag gcr.io/mymove/bolt-api
gcloud beta run deploy bolt-api \
--image gcr.io/mymove/bolt-api \
--platform managed \
--region europe-west1 \
--set-env-vars PROXY_KEY=***,BOLT_TOKEN=*** \
--no-allow-unauthenticatedChaque service est déployé dans la région europe-west1. Les services de scraping (bolt, kapten, g7, uber) sont privés, pas d’accès public. L’API centrale (new-api) est la seule exposée, protégée par JWT.
Pourquoi ça marche pour nous
- Isolation : un service qui plante ne fait pas tomber les autres. Si G7 change son HTML, seul
g7-apiest impacté. - Langages mixtes : Python pour les scrapers (requests, sessions, parsing HTML), Node.js/TypeScript pour l’API centrale et le SDK MySam. Chaque service utilise ce qui colle le mieux.
- Coût : avec le scale-to-zero, on ne paye que les requêtes réelles. Pour une app qui fait quelques centaines de recherches par jour, la facture GCP est dérisoire.
- Déploiement :
make prodet c’est poussé. Cloud Build construit l’image et la déploie en une commande.
Le vrai problème : des APIs qui n’existent pas
Aucun de ces fournisseurs (sauf MySam) ne propose d’API publique pour l’estimation de tarifs. On scrape. Et chaque fournisseur a sa propre façon de rendre les choses pénibles.
Bolt, l’endpoint mobile
Bolt expose un endpoint interne search.taxify.eu/findRideOptions utilisé par leur app mobile. On s’y connecte avec un token d’authentification généré à partir d’un numéro de téléphone et d’un UUID de device, exactement comme le ferait l’app sur un iPhone.
class Account:
def __init__(self, token, proxy=None):
self.token = token # Base64(phone:device_uuid)
self.proxy = proxy
def get_all_prices(self, _from, _to):
resp = requests.post(
"https://search.taxify.eu/findRideOptions",
headers={"Authorization": f"Basic {self.token}"},
json={
"pickup": {"lat": _from[0], "lng": _from[1]},
"destination": {"lat": _to[0], "lng": _to[1]},
},
)
return self._parse(resp.json())Le token expire régulièrement. Le service gère un retry automatique avec ré-authentification.
Kapten, la session mobile
Kapten (l’ancien Chauffeur Privé) expose api.kapten.com/v1/price. Même principe : on se fait passer pour l’app mobile avec un token d’authentification. La particularité, c’est qu’on maintient une session requests.Session() pour garder le compte connecté entre les requêtes. Ça évite de se ré-authentifier à chaque estimation.
# Kapten retourne des prix en centimes par catégorie
def _parse_prices(self, data):
result = {}
for item in data:
product = item.get("product_type")
if product in ("standard", "sedan", "van"):
min_price = item["price_min_cents"]
max_price = item["price_max_cents"]
result[product] = (min_price + max_price) / 2 / 100
return resultG7, le scraping HTML
G7, c’est le cas le plus tordu. Pas d’API du tout, on scrape le formulaire d’estimation du site g7.fr. Le flow en quatre étapes :
- On charge la page d’accueil pour extraire le token CSRF
- On convertit les Google Place IDs en identifiants internes G7 (TWSID), les deux conversions en parallèle via un pattern
Promise.all()maison en threading Python - On POST le formulaire d’estimation avec les TWSID et le token CSRF
- On parse le HTML de la réponse pour extraire le prix et la durée estimée
Le pattern Promise maison en Python (basé sur threading) lance les deux résolutions TWSID en parallèle. Sans ça, on double le temps de réponse pour G7.
class Promise:
def __init__(self, fn, *args):
self.result = None
self.exception = None
self.thread = Thread(target=self._run, args=(fn, *args))
self.thread.start()
def join(self):
self.thread.join()
if self.exception:
raise self.exception
return self.result
@staticmethod
def all(*promises):
return [p.join() for p in promises]Uber, l’endpoint frontend
Uber, c’est le plus propre des hacks. Leur site web utilise un endpoint interne uber.com/api/loadFEEstimates pour afficher les estimations côté client. On tape dessus directement depuis un serveur Node.js/Express :
const response = await axios.post(
"https://www.uber.com/api/loadFEEstimates",
{
origin: { latitude: from_lat, longitude: from_lng },
destination: { latitude: to_lat, longitude: to_lng },
},
{
headers: {
"x-csrf-token": "x",
"Content-Type": "application/json",
},
}
);Le x-csrf-token: "x" est un leurre, l’endpoint ne vérifie pas réellement le token CSRF quand on forge la requête correctement. On normalise ensuite les résultats pour notre format interne : UberX → classique, Berline → berline, Van → van, Green → green.
MySam, la seule vraie API
MySam est le seul fournisseur qui propose une API REST documentée. J’ai écrit un SDK TypeScript complet pour l’intégrer proprement :
// mysam-api, client TypeScript avec types exhaustifs
const mysam = new APIClient({
subdomain: "api.demo",
apiKey: "9014e53c-3243-4f51-b9ed-7f6c23739707",
});
const estimation = await mysam.estimation.estimate({
from: { lat: 48.8566, lng: 2.3522 },
to: { lat: 49.0097, lng: 2.5479 },
vehicleType: "CAR",
});Le SDK expose des types discriminés pour chaque endpoint, des type guards pour les erreurs, et une gestion propre des sessions. C’est le seul module du projet où le typage était exhaustif dès le départ, et c’est ce qui m’a convaincu de pousser TypeScript sur le reste du code Node.js.
Remontée async des résultats : Firebase Firestore
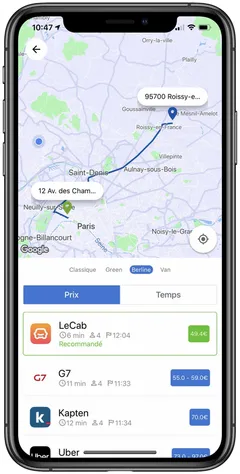
La latence, c’est le problème numéro un. Chaque fournisseur répond dans un délai différent : G7 est le plus lent (2-3 requêtes HTTP séquentielles), Uber le plus rapide. Attendre que tous répondent avant d’afficher quoi que ce soit, c’est faire poireauter l’utilisateur 3 à 5 secondes devant un spinner.
D’où l’affichage progressif. L’app lance les requêtes en parallèle, et chaque résultat s’affiche dès qu’il arrive, via un listener Firebase Firestore.
Côté React Native, le listener Firestore déclenche un re-render à chaque nouveau document :
firestore()
.collection(`${firestorePath}/results`)
.onSnapshot((snapshot) => {
const results = snapshot.docs.map((doc) => doc.data());
setFirebaseResults(results);
});L’utilisateur voit les résultats apparaître un par un, triés par prix ou par temps d’attente. Pendant que G7 fait ses trois requêtes HTTP, Uber et Bolt ont déjà affiché leurs tarifs. Le skeleton loading donne un feedback immédiat : on sait que des résultats arrivent.
TypeScript à la rescousse
Quand j’ai repris le projet, le code TypeScript existait uniquement dans l’API centrale (NestJS) et dans le SDK MySam. Le reste, les scrapers Python et l’Uber fake API en JavaScript vanilla, n’avait aucun typage.
Mon premier réflexe a été de consolider ce qui pouvait l’être. Pas question de tout réécrire en TypeScript (Python reste le bon choix pour le scraping HTTP avec requests). Mais partout où Node.js intervenait, j’ai poussé le typage.
L’API centrale : NestJS et le typage métier
L’API new-api tourne sur NestJS 7 (sorti en mars) avec TypeORM pour MySQL. Le framework impose une structure (modules, controllers, services, DTOs) qui se marie bien avec TypeScript. Les entités métier sont typées :
@Entity()
export class ProviderResultEntity {
@PrimaryGeneratedColumn()
id: number;
@Column()
providerId: string;
@Column()
providerName: string; // "Bolt" | "Kapten" | "G7" | "Uber"
@Column({ default: "EUR" })
currency: string;
@Column()
amountMinCents: number;
@Column()
amountMaxCents: number;
@ManyToOne(() => SearchEntity, (search) => search.providerResults)
search: SearchEntity;
}Tous les résultats des fournisseurs convergent vers ce format normalisé. Que le prix vienne en centimes (Kapten), en euros (Bolt), en fourchette min/max (G7) ou en tarif fixe (Uber), tout finit dans amountMinCents / amountMaxCents.
Le SDK MySam : les union types au service du métier
Le SDK MySam est le morceau le plus satisfaisant du projet côté typage. Les union types de TypeScript permettent d’exprimer les contraintes métier directement dans les types :
// Les paramètres de paiement sont mutuellement exclusifs
type PaymentParams =
| { paymentMethod: "IN_APP" | "DEFERRED" }
| { paymentMethod: "ON_BOARD"; willBePaidInCash: boolean };
// Un Van peut transporter jusqu'à 8 passagers, une voiture 4 max
type VehicleParams =
| { vehicleType: "VAN"; passengerCount: 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 }
| { vehicleType: "CAR" | "LUXE"; passengerCount: 1 | 2 | 3 | 4 };Les type guards permettent un error handling exhaustif :
try {
const trip = await mysam.trips.create(params);
} catch (error) {
if (isTripError(error)) {
switch (error.type) {
case "NO_DRIVER_AVAILABLE":
// retry dans 30s
break;
case "THIRD_PARTY_CALL_FAILED":
// fallback sur un autre fournisseur
break;
case "INVALID_PAYMENT_METHOD":
// demander à l'utilisateur de mettre à jour sa carte
break;
}
}
}Ce niveau de typage, sur un projet où cinq fournisseurs retournent des formats différents et où les erreurs sont la norme plutôt que l’exception, c’est un vrai filet de sécurité. On attrape les incohérences à la compilation, pas en production à 23h un vendredi.
La normalisation des résultats
Chaque fournisseur retourne un format différent. Le travail de normalisation est réparti entre les microservices (qui font un premier nettoyage) et l’app (qui unifie tout dans un format d’affichage).
Le mapping des types de véhicules illustre bien la complexité cachée derrière cette normalisation. Bolt a “Bolt”, “Berline”, “Green”, “Van”. Uber a “UberX”, “Berline”, “Green”, “Van”. Kapten a “standard”, “sedan”, “van”. G7 n’a qu’un seul type. Il faut ramener tout ça à quatre catégories : classique, berline, green, van.
Authentification et paiement
L’API centrale gère l’authentification via Firebase Auth côté mobile et JWT côté serveur. L’inscription se fait par numéro de téléphone (vérification SMS via Twilio) ou via Google/Facebook. Le paiement passe par Stripe : l’utilisateur enregistre une carte, et la réservation MySam (le seul fournisseur qu’on peut appeler programmatiquement) est facturée directement.
@Module({
imports: [
TypeOrmModule.forRoot(ormConfig),
AuthModule, // JWT + Firebase
UsersModule, // Profils utilisateurs
SearchesModule, // Historique des recherches
ProviderResultsModule, // Résultats normalisés
OrdersModule, // Réservations MySam
StripeModule, // Paiement par carte
ValidationCodeModule, // SMS Twilio
],
})
export class AppModule {}La base de données est un Cloud SQL (MySQL) connecté via Unix socket, la façon standard de relier Cloud Run à Cloud SQL. TypeORM gère les migrations automatiquement au démarrage.
Les galères du scraping en production
Scraper des APIs privées en production, c’est un sport d’endurance.
Les tokens Bolt expirent sans prévenir. Le service doit détecter un 401, régénérer un token, et retenter. Kapten est plus stable grâce à la session persistante, mais il faut plusieurs comptes pour encaisser le trafic sans se faire bloquer.
Les changements d’API sans préavis, c’est le quotidien. Bolt a changé de taxify.eu à bolt.eu du jour au lendemain. G7 refait son site, le sélecteur CSS #estimation-total disparaît. Uber change la structure de sa réponse JSON. L’avantage de l’isolation par microservice : chaque cassure est localisée.
Pour le rate limiting, les services utilisent des User-Agent réalistes (spoofés comme des clients iPhone), des proxys Crawlera pour la rotation d’IP, et des sessions persistantes pour ressembler à de vrais utilisateurs. Fragile, mais ça tient.
Et puis il y a la latence cumulée. Un cold start Cloud Run + un scraping G7 en trois étapes, ça peut monter à 5-6 secondes. L’architecture async avec Firestore absorbe ça côté UX (l’utilisateur voit les résultats rapides en premier) mais le budget latence reste serré.
Ce qu’on en retient
L’architecture microservices fonctionne bien pour ce use case précis. Quand chaque service correspond à un fournisseur externe avec sa propre logique, ses propres tokens et ses propres modes de défaillance, l’isolation est un vrai bénéfice. Le surcoût opérationnel (cinq Dockerfiles, cinq déploiements) est compensé par Cloud Run qui rend le tout gérable.
TypeScript change la donne dès qu’on normalise des données hétérogènes. Cinq fournisseurs, cinq formats de réponse, cinq types d’erreurs. Sans types, on navigue à l’aveugle. Le SDK MySam m’a convaincu que les union types et les type guards capturent des contraintes métier que les tests seuls laissent passer.
Le scraping d’APIs privées reste fragile par nature. Ça fonctionne aujourd’hui, mais chaque fournisseur peut décider demain de casser la compatibilité. L’architecture isole les dégâts sans les empêcher.
Pour un projet repris en cours de route avec une base de code bancale, la combinaison Cloud Run + TypeScript + microservices isolés a permis de remettre de l’ordre sans tout réécrire. Parfois la meilleure architecture est celle qu’on hérite et qu’on consolide, pas celle qu’on aurait dessinée sur un tableau blanc.